Dear friends in our factory we are using R, S, T GE Mark VIe Controller to running 32MW capacity turbine.
Normally a controller is selected as a designated (DC) controller.
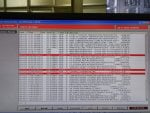
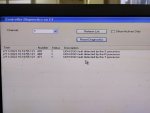
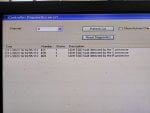
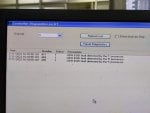
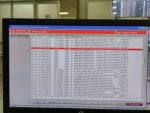
But in our factory about 1.5 to 2 hours later two or three controllers are automatically selected DC controller at a time showing Communication lost from R /S /T PROCESSOR.
For that the machine is tripped.
Before DC selected some error are visible such as UDH EGD fault detected by S or R or T processor.
In favour of this error we already checked Switch, Ethernet cables from controller to IO cards & Controller to Cisco switch, Cisco switch to PC etc and found ok.
We also change the controller for removing EGD fault but failed.
Dear friends anybody face this problem and how you solve this issue.
Normally a controller is selected as a designated (DC) controller.
But in our factory about 1.5 to 2 hours later two or three controllers are automatically selected DC controller at a time showing Communication lost from R /S /T PROCESSOR.
For that the machine is tripped.
Before DC selected some error are visible such as UDH EGD fault detected by S or R or T processor.
In favour of this error we already checked Switch, Ethernet cables from controller to IO cards & Controller to Cisco switch, Cisco switch to PC etc and found ok.
We also change the controller for removing EGD fault but failed.
Dear friends anybody face this problem and how you solve this issue.