 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinThe Importance of Development: Creating a Strategy for Dataflow Management
Smart greenfield design unlocks clean, scalable dataflow. Learn how defining KPIs, choosing open architecture, contextualizing data, leveraging edge computing, and using the cloud wisely can transform operations from day one.
The development of greenfield systems gives automation engineers a unique opportunity to plan out dataflow management from the very beginning. Instead of having to manage legacy equipment, sort out data silos, mix protocols, and interfere with fragile data operations, engineers can plan out all of the important parts of data: who generates it, where it goes, and how it is used.
Poor planning in this stage leads to all of the problems one would expect. Everything from data that is inaccessible to the proper consumer, to corrupted data, to burdensome, cryptic databases that are virtually unusable; all of these are possible without proper planning. Therefore, it is imperative that engineers include a comprehensive dataflow management strategy as part of the design process for greenfield systems.
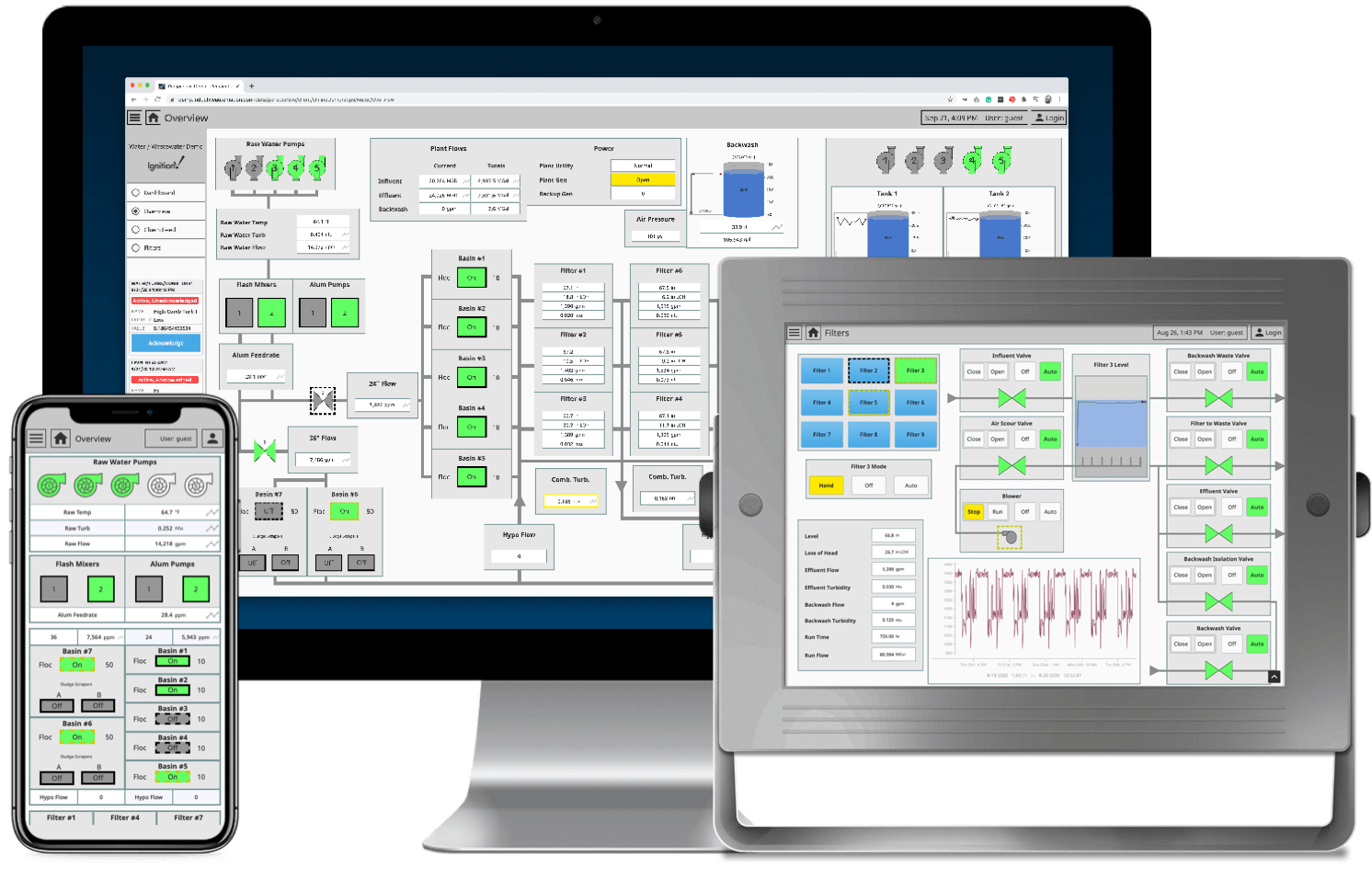
Figure 1. Data is dashboards, but it is also planning out which datasets are sent to which locations, who has access, what to collect, and how to store it. Image used courtesy of Inductive Automation
Five Common Questions for Greenfield Operations
During the design process for greenfield operations, automation engineers should carefully plan out how data will flow through the system. End users need to understand how, where and why data is collected and stored. They also need to be convinced that the data will be accurately modeled and portrayed in digital twins. While planning the dataflow management strategy, a few questions will naturally arise and can be lumped into these five basic questions.
1. What are the Business Objectives?
Before making any purchases of hardware or software, the first question to ask is this: What are the objectives of this business, and what process variables and Key Performance Indicators (KPIs) should be tracked? If one starts by purchasing equipment, the temptation is to track what the software wants to track versus what the business actually needs to track.
Potential objectives might be to get information to the stakeholders about process dynamics for decision-making purposes, or to develop models for forecasting or predictive maintenance. The very first discussion of data in greenfield operations should establish what KPIs need to be tracked and for what purposes.
With modern advancements in AI and Machine Learning, many devices have these capabilities built in. Design engineers should decide how and if they would like to leverage these technologies, and which inputs and outputs will be required and desired during the planning stages.
2. How Should Digital Infrastructure be Arranged?
Perhaps the most important question is this: How should the digital infrastructure be constructed? Protocols, formats, and templates must be chosen early in the design process to make the whole system scalable. For greenfield systems, engineers get to start from scratch and do not have to work around existing data systems, making it easier to structure the dataflow correctly from the beginning.
Once again, starting with applications or software packages tends to lead to a brittle, unscalable system. Instead, a better approach is to decouple data from software and instead take on a data-first approach to planning. A Unified Namespace (UNS) can be implemented, and that will allow data to be accessed across the enterprise, regardless of software or platform. Also, choosing open software and protocols prevents the system from being tied to a specific vendor, who may have proprietary conventions.
3. What is the Best Strategy for Data Contextualization?
A common saying in data analysis is “data without context leads to a data swamp.” Or, put bluntly, “data without context is virtually worthless. Therefore, an important part of developing a dataflow management is to add the necessary context for what the data means and how it will be collected.
One general rule of thumb is that data contextualization should be performed as close to its collection point as possible. This means data contextualization should ideally be performed at the edge, using edge computers. However, just because the data is collected at the edge should not limit its interoperability with other systems. Data can be standardized using OPC-UA and CESMII smart manufacturing profiles so that it can be easily understood across platforms.
It must be clear, at all times, whether a collected dataset is part of an asset, machine, or final product. Furthermore, those datasets should be standardized among types. For example, consider a set of extruders that come from a variety of manufacturers and are of varying ages. While data collection may vary between extruders, there needs to be a standard data template that defines the important parameters for all of the extruders.
Standardization and contextualization allow for the creation of digital mirrors and digital twins, or ways to simulate production electronically. In either case, changes to the system can be modeled before implementation to look for weak points or throttle points for production. These models can also be used for looking for opportunities to enhance efficiency without costly downtime. The more accurate the data contextualization and modeling, the more likely changes can be made at minimal loss of production.
4. How Does Edge Computing Fit into the Overall Strategy?
Edge computing has the potential to take some of the computational load off the main system. The general idea is to have edge computers and controllers make decisions locally, and then relay only the relevant process information back to the central control system. This saves on network bandwidth, computational time on the most expensive hardware, and speeds up response, as data does not need to make a round trip before a process decision is executed.
.png)
Figure 2. Technicians can check local data at the edge computer and verify operations. Image used courtesy of Inductive Automation
For the greenfield system, developing an edge computing plan means deciding which data needs to be forwarded and which can be consumed at the local control point. Without a plan, the temptation is to transmit all data back to the central control system, which defeats the purpose of edge computing in the first place.
So, when is edge computing useful? Machine-level decisions can be performed at the machine. Modern edge computers, especially those with onboard Graphics Processing Units (GPUs) can handle many calculations and even some modeling and AI/ML algorithms locally. This allows for high-speed decision-making to occur locally, versus having to worry about latency in cloud communications. Also, local data collection means preservation of fragile data that could be lost during communication interruptions with cloud-based servers.
5. How Will the Cloud Enhance Operations?
The growth of cloud computing and cloud storage has allowed industry to reduce its internal computing load. Data is stored in the cloud using data lakes and data warehouses, and does not require many specialized personnel to maintain and secure this data in-house. Instead, upgrades, security, and other such features are contracted out as a service. However, sending data to the cloud does take some of the control away from internal users, adds to the expense of the operation, and leads to other concerns.
Before dumping all data and modeling capabilities to the cloud, engineers working on a greenfield project should carefully consider how the cloud will enhance their operations. Not all data and modeling capability needs to (nor should be) sent to the cloud. Stated another way, cloud computing should only be used where it adds value to the operation.
One powerful model is a hybrid system where some information is kept on premises and some is sent to the cloud. Cloud computing can handle long-term data storage, advanced analytics that may be difficult to develop in-house, manage some aspects of OT machine health and metrics, and allow for remote operations and enterprise-level visibility of data.
In greenfield applications, planning out what data will go to the cloud and what stays with the in-house MES at the beginning will save headaches and troubleshooting effort in the long run.
Inductive Automation Can Make It Happen
Developing a dataflow management strategy involves answering these five questions before purchasing hardware or software, or developing code in-house. Greenfield operations have the advantage that they can be designed to be scalable from the beginning, and the development of a comprehensive dataflow management strategy is essential.
To learn more about how to develop an effective dataflow management strategy, answer these five questions and build a scalable, secure and efficient plan for your greenfield operation, reach out to the experts at Inductive Automation. They have years of experience in developing integrated dataflow management systems and can help you make sense of all of the technical details to make your plant work effectively.
Related Content













Excellent… “data without context is virtually worthless”