 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinDigital Representation of Text
Binary patterns are not just able to represent numerical values. Given a standardized code, they may represent other types of data as well, such as alphabetical characters. The ability to encode non-numerical data in digital form is what allows computers to manipulate and communicate text. In this subsection, we will explore some of the ways language characters are digitally encoded.
The representation of text by discrete (on/off) signals is rooted in ancient practice. The Greek historian Polybius described one such system in his Histories written in the second century BCE, used to communicate information about military maneuvers. In this passage Polybius describes the problem posed by primitive fire signals, and presents an improved method:
“It is evident to all that in every matter, and especially in warfare, the power of acting at the right time contributes very much to the success of enterprises, and fire signals are the most efficient of all the devices that aid us to do this. For they show what has recently occurred and what is still in the course of being done, and by means of them anyone who cares to do so even if he is at a distance of three, four, or even more days’ journey can be informed. So that it is always surprising how help can be brought by means of fire messages when the situation requires it. Now in former times, as fire signals were simple beacons, they were for the most part of little use to those who used them. It was possible for those who had agreed to convey a signal that a fleet had arrived in Oreus, Peparethus, or Chalcis, but when it came to some of the citizens having changed sides or having been guilty of treachery or a massacre having taken place in town, or anything of the kind, things that often happen, but cannot all be foreseen – and it is chiefly unexpected occurrences which require instant consideration and help – all such matters defied communication by fire signal. It was quite impossible to have a preconceived code for things which there was no means of foretelling.
This is the vital matter; for how can anyone consider how to render assistance if he does not know how many of the enemy have arrived, or where? And how can anyone be of good cheer or the reverse, or in fact think of anything at all, if he does not understand how many ships or how much corn has arrived from the allies?
The most recent method, devised by Cleoxenus and Democleitus and perfected by myself, is quite definite and capable of dispatching with accuracy every kind of urgent messages, but in practice it requires care and exact attention. It is as follows: We take the alphabet and divide it into five parts, each consisting of five letters. Each of the two parties who signal to each other must get ready five tablets and write one division of the alphabet on each tablet. The dispatcher of the message will raise the first set of torches on the left side indicating which tablet is to be consulted; i.e., one torch if it is the first, two if it is the second, and so on. Next he will raise the second set on the right on the same principle to indicate what letter of the tablet the receiver should write down.”
We no longer use burning torches to convey information over long distances, but we do face a similar challenge: how might we convey messages of arbitrary length and complexity using a limited range of signals? Like Polybius, many modern solutions are based on encodings of an alphabet, which then may be used to communicate any message reducible to written language.
Morse and Baudot codes
In the early days of communication, Morse code was used to represent letters of the alphabet, numerals (0 through 9), and some other characters in the form of “dot” and “dash” signals. Each “dot” or “dash” signal is one bit of data, equivalent to “1” and “0”. In the International Morse Code, no character requires more than five bits of data, and some (such as the common letters E and T) require only one bit.
A table showing how International Morse code represents all characters of the English alphabet and the numerals 0 through 9 appears here:

The variable bit-length of Morse code, though very efficient in terms of the total number of “dots” and “dashes” required to communicate text messages, was difficult to automate in the form of teletype machines. In answer to this technological problem, Emile Baudot invented a different code where each and every character was five bits in length. Although this gave only 32 characters, which is not enough to represent the 26-letter English alphabet, plus all ten numerals and punctuation symbols, Baudot successfully addressed this problem by designating two of the characters as “shift” characters: one called “letters” and the other called “figures.” The other 30 characters had dual (overloaded) meanings, depending on the last “shift” character transmitted.
EBCDIC and ASCII
A much more modern attempt at encoding characters useful for text representation was EBCDIC, the “Extended Binary Coded Decimal Interchange Code” invented by IBM in 1962 for use with their line of large (“mainframe”) computers. In EBCDIC, each character was represented by a one-byte (eight bit) code, giving this code set 256 (\(2^8\)) unique characters. Not only did this provide enough unique characters to represent all the letters of the English alphabet (lower-case and capital letters separately!) and numerals 0 through 9, but it also provided a rich set of control characters such as “null,” “delete,” “carriage return,” “linefeed,” and others useful for controlling the action of electronic printers and other peripheral devices.
A number of EBCDIC codes were unused (or seldom used), though, which made it somewhat inefficient for large data transfers. An attempt to improve this state of affairs was ASCII, the “American Standard Code for Information Interchange” first developed in 1963 and then later revised in 1967, both by the American National Standards Institute (ANSI). ASCII is a seven-bit code, one bit shorter per character than EBCDIC, having only 128 unique combinations as opposed to EBCDIC’s 256 unique combinations. The compromise made with ASCII versus EBCDIC was a smaller set of control characters.
IBM later created their own “extended” version of ASCII, which was eight bits per character. In this extended code set were included some non-English characters plus special graphic characters, many of which may be placed adjacently on a paper printout or on a computer console display to form larger graphic objects such as lines and boxes.
ASCII is by far the most popular digital code for representing English characters, even today. Nearly every digital transmission of English text in existence employs ASCII as the character encoding. Nearly every text-based computer program’s source code is also stored on media using ASCII encoding, where 7-bit codes represent alphanumeric characters comprising the program instructions.
The basic seven-bit ASCII code is shown in this table, providing conversions to decimal, hexadecimal, and binary, all of which are useful within various contexts. For example, the ASCII representation of the upper-case letter “F” is 1000110, the ASCII representation of the equal sign (=) is 0111101, and the ASCII representation of the lower-case letter “q” is 1110001.
ASCII Code Set
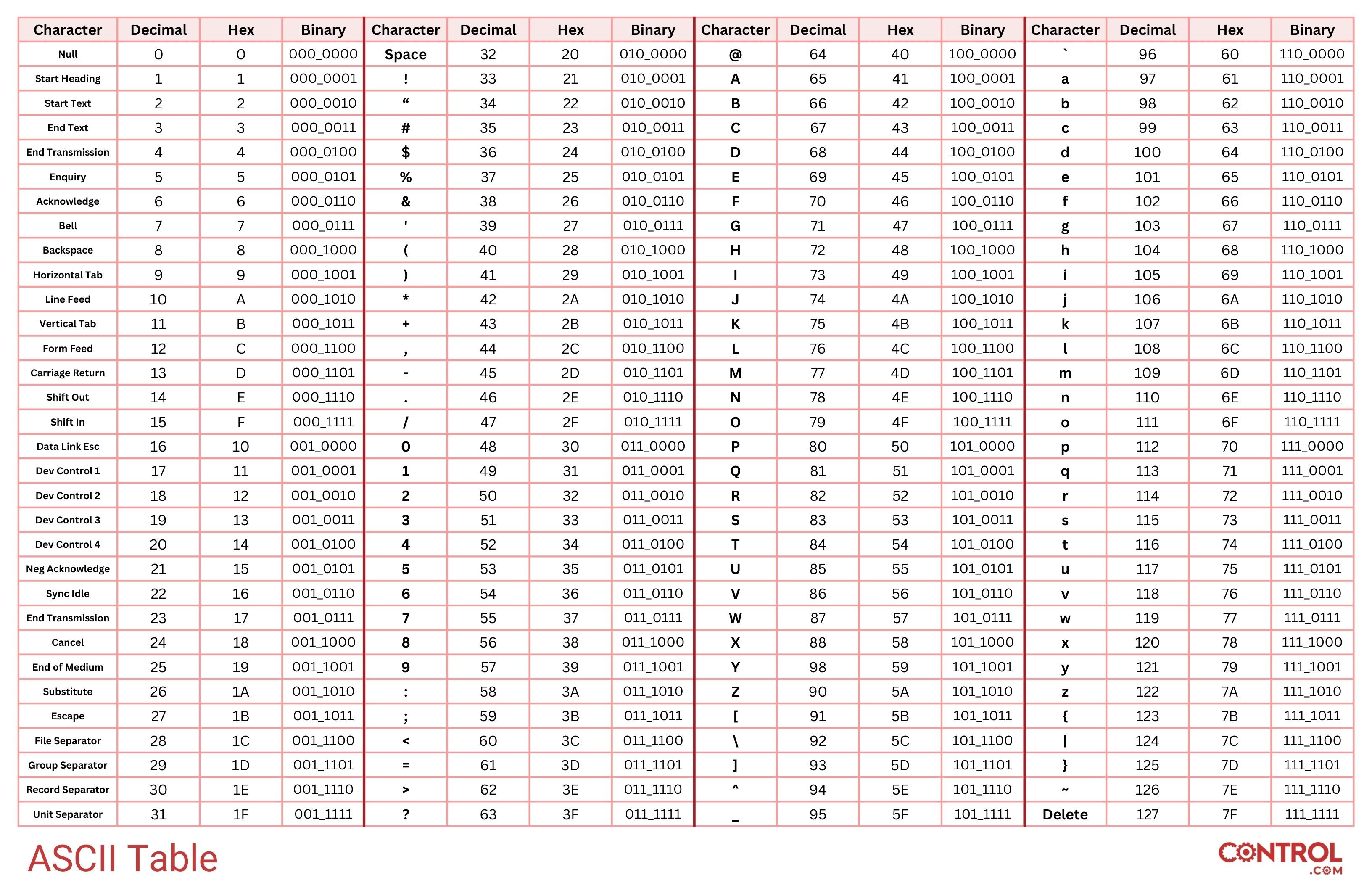
Convenient high-res ASCII table showing Dec, Hex, and Bin numbering conversions. (Click for a large-size version)
The aforementioned “control characters” occupy the “000” and “001” columns of the table. These characters, while not associated with a printed character on the page, nevertheless play roles the other “visible” characters cannot. The “LF” character (“line feed”), for example, tells the printer to go to the next line on the paper. The “CR” character (“carriage return” or, as we call it in modern days, "enter") tells the printing head to return to the left-hand side of the paper. The “ESC” character (“escape”) does not result in a printed character on paper, nor does it usually command a printing machine to do anything specific, but it is often used within software as a signal to jump up one level in a menu structure, or to switch modes.
Unicode
There exist many written languages whose characters cannot and are not represented by either EBCDIC or ASCII. In in attempt to remedy this state of affairs, a new standardized code set is being developed called Unicode, with sixteen bits per character. This large bit field gives 65536 possible combinations, which should be enough to represent every unique character in every written language in the entire world. In deference to existing standards, Unicode encapsulates both ASCII and EBCDIC as sub-sets within its defined character set.
And no, I am not going to include a table showing all the Unicode characters!
