Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinData Science for Control Systems
Data science is a multidisciplinary field crucial to modern automation. In this article, learn about data science concepts and best practices.
Data science is an applied science whose scope is repeatedly redefined. This is because this field pertains to data analysis, and the amount of data available and consumed worldwide is growing extremely fast. For context, the total amount of data created and consumed in the world in 2020 was estimated at 64.2 zettabytes. In 2024, that number is projected to be 149 zettabytes, more than double 2020. One zettabyte equals one trillion gigabytes.
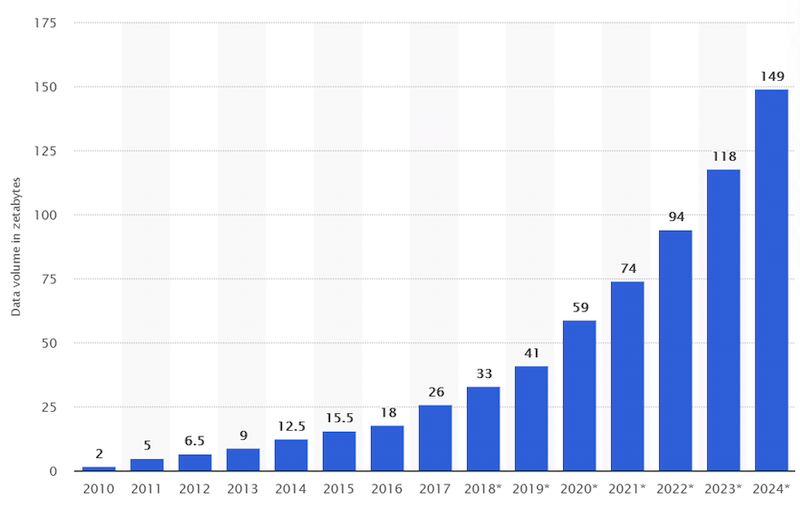
Figure 1. Worldwide data volume consumed per year in the last decade and projections for the next years. Image used courtesy of Blend Berisha
The first definition of data science, coined in the 1960s, paired this field with something much more strictly about statistics, which perdured throughout the last century. In the early 2000s, as the personal computer and internet era started to take hold, the concept of data science started to shift toward computer science.
Nowadays, it is nearly impossible to conceive one without the other. In the past two decades, in parallel to the growth of data explained in the previous graph, new data analysis-related terms emerged: big data, artificial intelligence (AI), and machine learning. Simultaneously, industrial automation systems became more vertically integrated, requiring more complex systems and data handling. All this converged—and is still converging—into a field that evolves while setting the standards for innovative developments.
The Data Science Lifecycle
Data science is multidisciplinary. It combines concepts and methods from other fields, such as computer science, statistics, mathematics, communication, and more. It also requires domain knowledge, which is understanding the specific field that the analyzed data belongs to.
Data scientists are the professionals who create algorithms, parse data, and communicate the outcomes in data science. They differ from data analysis and data engineers in the combination of skills required to perform their jobs. A data scientist needs to be proficient in computer programming, mathematics, statistical analysis, and data visualization.
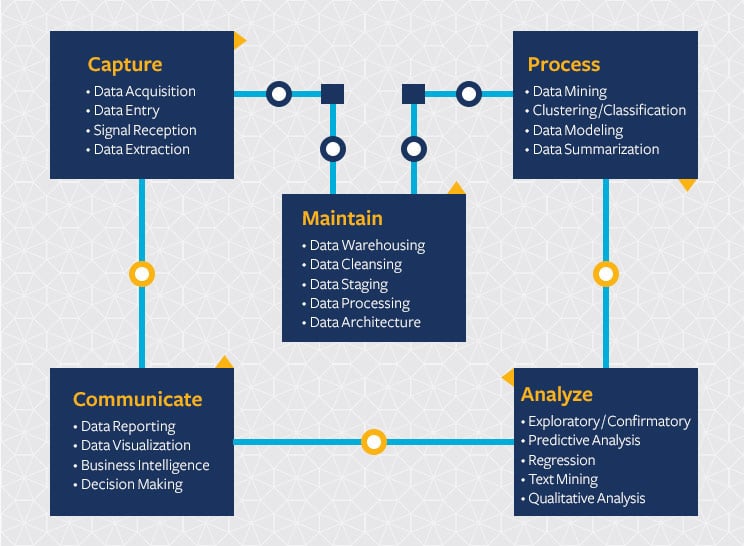
Figure 2. The data science lifecycle. Image used courtesy of UC Berkeley School of Information
The different steps that a data scientist must follow to complete an effective data science project are outlined in the recursive data science lifecycle model. This model constitutes a standard and defines best practices that can result in a successful data science project.
- Business understanding: After studying the business and its rules, the problem is defined, along with the criteria to evaluate the data science project outcomes.
- Data mining: Revolves around data acquisition that may directly or indirectly help solve the stated problem. The data storage architecture is defined in this step: data warehouse or data lake?
- Data cleaning: Involves relevant data selection and evaluating its completeness and integrity. If the data is deemed incorrect or insufficient, the data scientist can go back to the data mining step.
- Data exploration: This is the most flexible step, in which the data scientist takes several more looks at the curated data to define algorithms and create a model.
- Feature engineering: The data scientist uses their domain knowledge to mine and transform the data properly. This is also sometimes referred to as machine learning.
- Predictive modeling: Using techniques such as linear regression, predictions are made about future trends, and the model used is evaluated, making the process iterative.
- Data visualization: Good communication skills are necessary to produce meaningful reports and presentations that have the desired impact on the target audience.
Data Science and Automation
Automation is perhaps the best positioned to gain the most from data science. The volume of data generated by many modern and highly automated processes has entered the range of big data. Higher-level applications that manage floor-level controllers and devices can analyze large amounts of information to produce reports about a system’s conditions and trends.
Another important use for this information is to improve maintenance practices by enabling predictive maintenance. This is an automated data science flow that evaluates information obtained from different steps of a process, coming from a multitude of devices, which is then used to issue the best possible recommendations on a course of action for that system. In many cases, too, the system itself can autonomously execute correction steps.

Figure 3. Predictive maintenance makes use of large amounts of data provided in a highly automated system. Image used courtesy of AT&T
Computer vision and, in general, all vision systems, are another element of the automation world seeing important advancements thanks to data science. Vision systems are now required to perform several evaluations of an image in a matter of a few milliseconds. Not only is processing power crucial, but the data generated from the evaluation process can prove useful for future analysis and identification of system or product trends.
Although not quite related to industrial automation, autonomous driving features in vehicles are a good example of automated data science in vision systems. Vehicles are equipped with numerous sensors, LiDAR devices, and wireless instruments, all of which provide information to a central controller about the surrounding environment. The analysis result determines whether there are potential obstacles nearby and evaluates weather and traffic conditions.
Data science is necessary to utilize predictive maintenance, autonomous mobile robots (AMRs), or other automated technologies. Data science follows a cyclical pattern, meaning it is always in use. What processes do you use data science for in your facility?