 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinWhat is a Data Lake?
Learn the fundaments of data lakes and how they are important to digital transformation under Industry 4.0.
Broadly speaking, a data lake is a centralized repository of raw data. Data lakes have become an important element in the industry 4.0 transformation. The relationship between these two concepts lies in the need to capture and analyze ever-growing amounts of information, entering the realm of big data. To better understand data lakes, let’s first look into some historical context and the predecessors of this type of repository.
A History of Data Repository Systems
The first conceptualized data repository was named data mart. First released in the 1970s, data marts were aimed at better organizing the information of different departments within a business. Purchasing, sales, and production areas would each have their own data mart configuration, containing structured information managed only by people within the same department.
Another form of data repository was called a data silo. They are very similar in principle to data marts, except they are more isolated. Back in the 1980s, this was viewed as a good security practice.
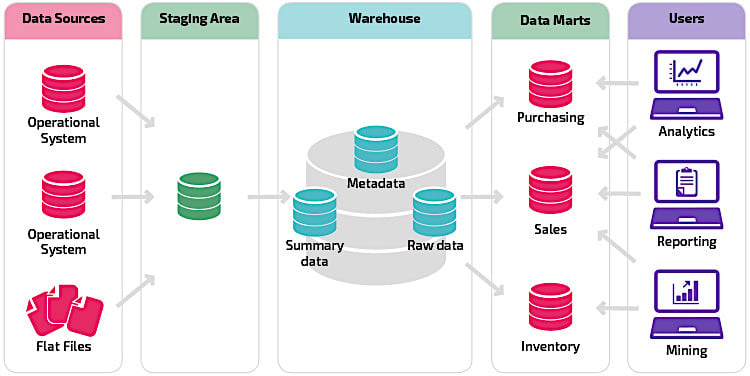
Figure 1. Data warehouses and marts are types of repositories traditionally used for managing information. Image used courtesy of Panoply
Then came data warehouses. In contrast to data marts and silos, data warehouses are more centralized, meaning information from different areas is concentrated in the same repository. In a certain way, data marts can be components of data warehouses.
An important characteristic of a data warehouse is that the information gathered in the repository has a specific purpose; or rather, the purpose of the information is known from the beginning, when the warehouse is designed. Why this is important will become clearer when we talk about data lakes.
Data warehouses are nowadays the predominant form of data repository in many fields. One of the most common forms of data warehouses used is relational databases (RDBs). RDBs organize data in one or more tables related to one another using links or keys. RDBs are queried using a relational database management system (RDBMS), employing languages such as SQL. The information contained within a data warehouse, such as a SQL database, is processed, and the results are the basis for making business decisions.
The term “data lake” was first used in 2010 to describe a large pool of raw unprocessed data. It was not the first time they were used, but they did not have an official name before. Over the last decade, functionalities and architectures have been developed to standardize as data lake usage grows.
Data Lake Fundamentals
Again, data lakes are central repositories of raw data. But is any raw data repository a data lake? No. Data lakes are large-scale depots of information that may be valuable in the future and whose purpose is not yet 100% known. Although this might indicate that the information is not organized, that is far from true. Data lakes are structured. During the design stage of a data lake, it is important to consider all the data inputs and outputs to create good architecture.

Figure 2. Common elements of a data lake architecture design. Image used courtesy of Guru99
Data lakes may receive both relational and non-relational databases, meaning that this does not make them mutually exclusive from data warehouses. A common misconception is that, because data lakes are relatively newer, they replace data warehouses. This is incorrect because they serve almost entirely different purposes and therefore are complementary data tools within a business.

Figure 3. An example of a data lake schema from a video advertising and monetization platform. Image used courtesy of Upsolver
The type of information that can be found in a data lake can be very varied and largely depends on the type of application and business. For instance, a social media data lake is going to capture different things than an online store. An industrial automation data lake would look even more different.
Data Lakes in Industrial Enterprises
Growing demands of data in some industries have reached sizes of Terabytes per day, entering ranges of what is defined as big data. This is largely driven by automation, where highly automated systems can log practically every action and transaction. Data lakes are essential to capturing this information, so it can later be analyzed and leveraged.
One field, in particular, that is seeing tremendous benefits from data lakes is predictive maintenance. An automated system with a carefully designed data lake will benefit from the availability of information that can predict issues and prevent them before they become actual problems. Several automation providers are developing new applications and tools for predictive maintenance, and we are likely to see many of these products soon. Predictive maintenance and machine learning are two concepts that are very closely linked.

Figure 4. Predictive maintenance is gaining relevance in the oil field automation industry due to the large amounts of data generated daily and the cost-benefits of avoiding incidents. Image used courtesy of Seeed Studio
Data lakes are projected to continue growing in importance in Industry 4.0. Beyond predictive maintenance, these repositories are also valuable in product design and product optimization. Other applications are likely to surface in the near future. What applications do you use data lakes for?












