 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinDeep Dive Into the Data Science Lifecycle
Learn the definition and basic steps of the data science life cycle, particularly the popular CRISP-DM model.
Since the arrival of big data, modern computer science has been reaching new capabilities and processing power benchmarks. Nowadays, it is not uncommon to find applications that produce data sets of 100 terabytes or more, which is considered big data.
With such large volumes of information at hand, it is easy to get disorganized and waste time with useless content. These are two reasons why it is very important to follow a methodology that increases the efficacy and efficiency of a big data project.

Figure 1. Modern data science works with very large data sets, also known as big data.
The data science life cycle provides a framework that helps define, collect, organize, evaluate, and deploy big data projects. It is an iterative process consisting of a series of steps arranged in a logical sequence, facilitating feedback and pivoting.
What does the life cycle sequence look like? The answer is, there isn’t a single universal model that everybody follows. Many companies undertaking big data projects adapt the data science life cycle to their business processes, typically including more steps. Despite this, all the many models and process flows have common denominators. This article will use the CRISP-DM process model, which is one of the first and most popular data science life cycle models.
The CRISP-DM Model
CRISP-DM stands for Cross Industry Standard Process for Data Mining. It was first published in 1999 by ESPRIT, a European program for boosting research in information technology (IT). The CRISP-DM model consists of six steps or phases that guide the big data project. It encourages stakeholders to think about the business by posing and answering important questions about the problem.
Let us review in detail the six phases of the CRISP-DM model.
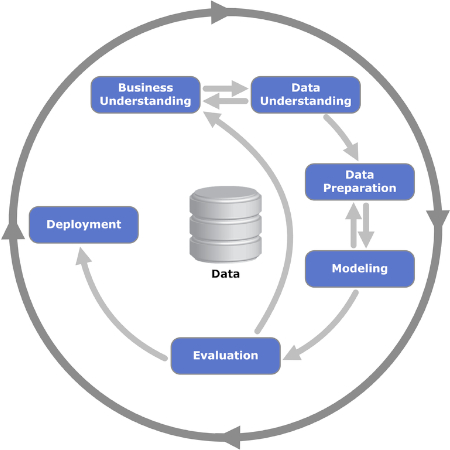
Figure 2. The iterative six phases of the CRISP-DM model are shown. Image used courtesy of Kenneth Jensen
Phase 1: Business Understanding
The first phase consists of several tasks that define the problem and establish goals. This is when the project objectives are set with the focus on the business—or, in other words, the customer. Normally, the team assembled to work on a big data project must deliver a solution to the customer, which can be another area or department within the company.
Once the business need or problem has been established, the next step is to define success criteria. These can be key performance indicators (KPI) or service level agreements (SLA), which provide objective means to evaluate progress and completion.
Next, the business situation needs to be analyzed to identify risks, rollback plans, contingency measures, and, more importantly, resource availability. A project plan is laid out, including milestones resources.
Phase 2: Data Understanding
Once the fundamentals have been established in the previous phase, it is time to focus on the data. This phase begins with an initial definition of what data is believed to be necessary, and then documents some specifics about it: where to find it, type of data, format, relationships between different data fields, etc.
With the first documentation ready, the next step is to execute the first data collection run. This provides a useful snapshot of how the structure is forming. This snapshot of information is then evaluated for quality.
Phase 3: Data Preparation
The third phase reinforces the previous phase and prepares the data set for modeling. Data fields from the first collection are further curated, and any information deemed unnecessary is removed from the set: This is called cleaning the data.
Also, a specific piece of information may need to be derived from other information available; other times, it must be combined. In other words, the data needs to be processed to produce a final format.
Phase 4: Modeling
The most important task in this phase is to select an algorithm to process the data collected. In this context, an algorithm is a set of sequence steps and rules programmed in computer software designed for big data projects.
Many algorithms can be used: linear regressions, decision trees, and support vector machines are some examples. Choosing the right algorithm to solve the problem requires skills that experienced data scientists have.
Figure 3. Linear regression is one type of algorithm used in big data modeling.
The next step is to code the algorithm into the software application. This is also when the testing phase is planned out, which consists of allocating specific data sets for testing and validation.
Phase 5: Evaluation
Sometimes, it is difficult to choose an algorithm from the start. When this happens, scientists execute several algorithms and analyze the results to reach a final decision. Once the testing phase is completed, the results are reviewed for completeness and accuracy.
More importantly, this is an opportunity to assess whether the results lead toward a solution. In the iterative model, this is a crucial intersection where major iteration sequences can be launched, or a decision to move toward the final phase can be reached.
Phase 6: Deployment
This is when the project moves from a testing environment to a live production environment. Planning the deployment schedule and strategy is very important to reduce risks and potential system downtime.
Although the model diagram suggests that this is the end of the project, there are still numerous steps to follow up afterward: monitoring and maintenance. Monitoring is a period of close observation, also known as hyper care, immediately after go-live. Maintenance is a semi-permanent process for maintaining and upgrading the implemented solution.
Big data is called so for a reason: There is a massive amount of data to parse through. Implementing one of the data science lifecycle models helps decide what information is worthy to keep and use for processes such as predictive maintenance.











